Power Automateでタブ文字を取り除いたり、タブ区切りで配列にしたりする
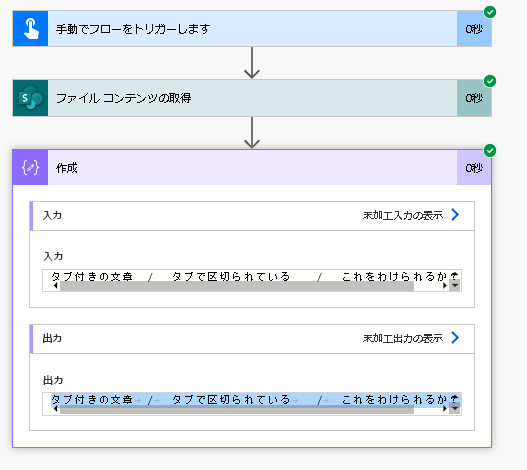
届いたメールの内容から必要項目を抜き出してファイル化しようとしたときに、タブ文字で空白を開けているものがありました。タブを区切りとして配列に分けたり、タブを取り除いたりする方法を紹介します。
Power Automateで見えない改行文字を処理する方法はよく解説されているのですが、結構探してもタブ文字の処理については情報がほとんどなかったので参考にしていただけると嬉しいです。
まず、テキストエディタでタブ文字を含んだ文字列を作っておきます。日本語の文字をつかうと後で見分けがつきにくいので、まずはアルファベットだけでテストします。
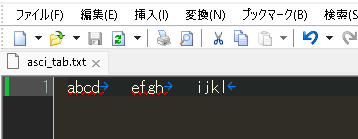
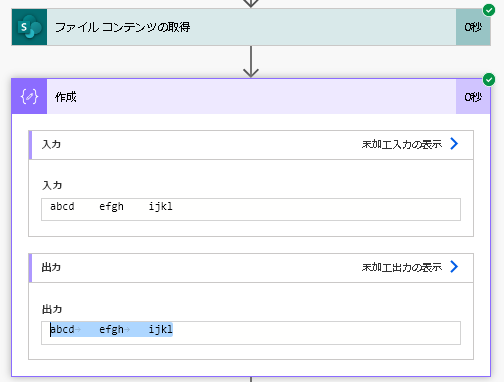
このテキストファイルをSharePointに置き、Power Automateで読み込んで見ると、うっすらと「→」マークが見え、ここにタブ文字が含まれていることがわかります。
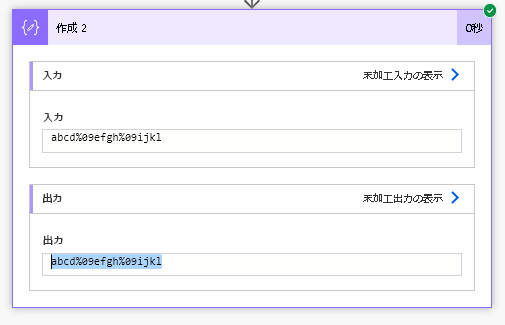
タブ文字もコードを持っているはずなので、encodeUriComponent関数を使ってどんなコードが使われているのかを解析します。
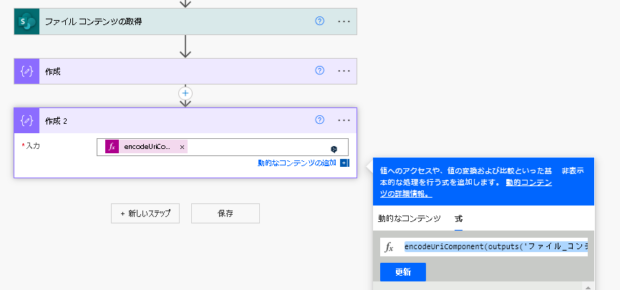
encodeUriComponent(outputs('ファイル_コンテンツの取得')?['body'])結果は以下のとおり。タブ文字は「%09」だということがわかりました。
ということは、この%09を取り除くにはreplace関数を使えばよいですし、配列に分割したければsplit関数を使えばよいですね。解析にはencodeUriComponent関数を使いましたが、今度はその逆でdecodeUriComponent関数を使います。
replace(outputs('ファイル_コンテンツの取得')?['body'],decodeUriComponent('%09'),'')split(outputs('ファイル_コンテンツの取得')?['body'],decodeUriComponent('%09'))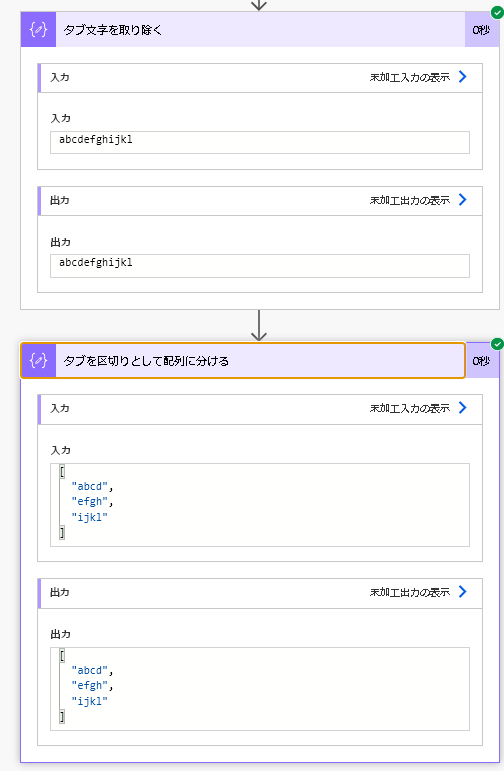
いい感じに処理ができました!
タブがエンコードできるということは、ほかの見えない文字も?
ちなみに、改行したテキストを読み込ませ、encodeUriComponent関数を通してみると、「%0D%0A」になりました。
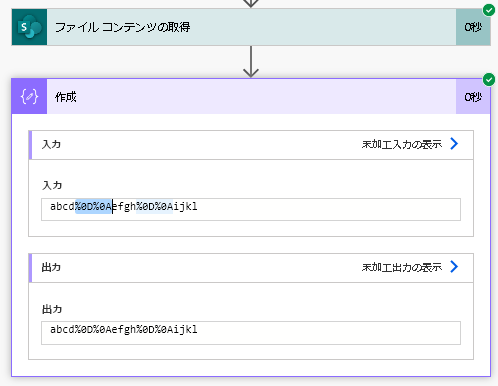
ASCII制御コード表というのがありまして、それを確認してみます。
https://e-words.jp/p/r-ascii.html
| 13 | 0d | CR | Carriage Return | 行頭復帰 |
| 10 | 0a | LF / NL | Line Feed / New Line | 改行 |
16進数の0dは「CR」、0Aは「LF」となっています。どこかで見たことがある記号。改行コードはこの2つの見えない文字で制御されています。改行といってもWindows、Mac、Linuxのそれぞれ歴史的な経緯で使われている改行コードが違います。詳しくはWikipediaなどをどうぞ。
見えない制御文字も扱える
制御文字もencodeUriComponent関数を使えば扱えることがわかりました。他にもPower Automateの逆引きTIPSのようなものをまとめていますので、参考にしていただけると嬉しいです。