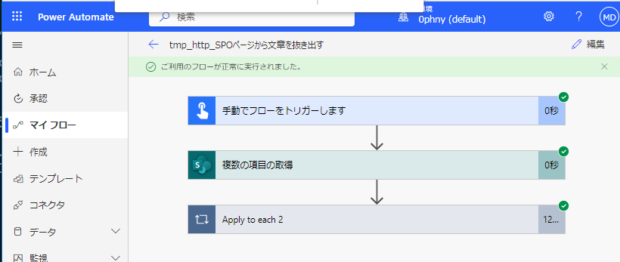
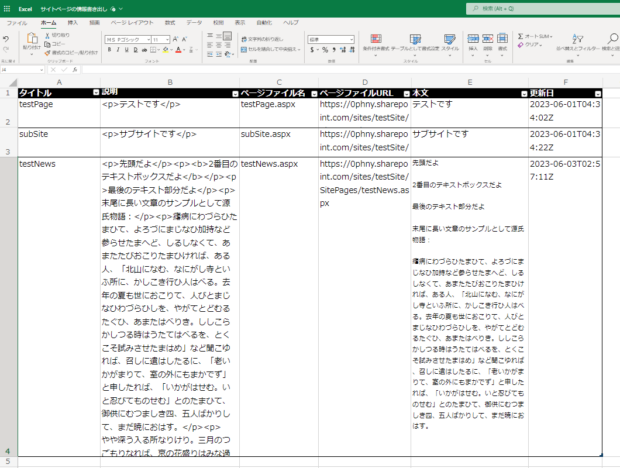
SharePointのサイトページの本文をすべてExcelに書き出す
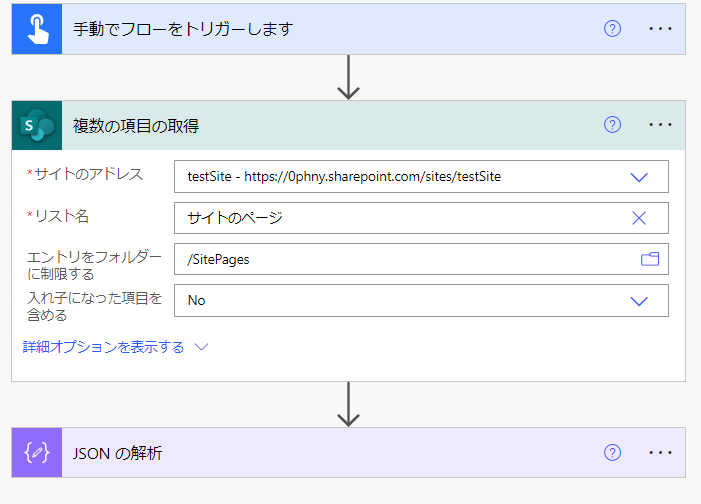
SharePoint上に作成したニュースやページの内容を取得して、Excelに書き出す方法を試してみます。SPOにはExcelへエクスポートする機能も付いているのですが、管理者以外には解放されていないような場合でも、Power Automateでからなら出力できますし、なにか条件を加えてやるこもと簡単です。
Qiitaの記事に、「サイトのページ」から、ページを管理しているSPOリストを取得する記事を書きましたので先にそちらをチェックしてください。
https://qiita.com/DaddyDaddy/items/1918c4fcd68ae93546e7
一覧では本文の一部しか表示されない。
サイトのページの非表示列から「説明」列を加えてやると、ページの中に書いてある文章が取り出せます。しかし、よく見ると最後のほうが・・・となっていて省略されています。どうやら、先頭から250文字以降は取り除かれてしまうようです。
これは、Excelにエクスポートのボタンから書き出した場合にも同様で、ページの内容テキストをすべて取り出したい場合には、この方法では役に立ちません。
こまったときの HTTP要求
SharePoint関連でちょっと凝ったことを行うときに使えるのは、Power Automateの「SharePointにHTTP要求を送信します」アクションです。
各ページのIDを利用するために、ID列を表示させます。ヘッダー部分の下矢印部分をクリックし、「列の設定」>「列の表示/非表示」を開きます。
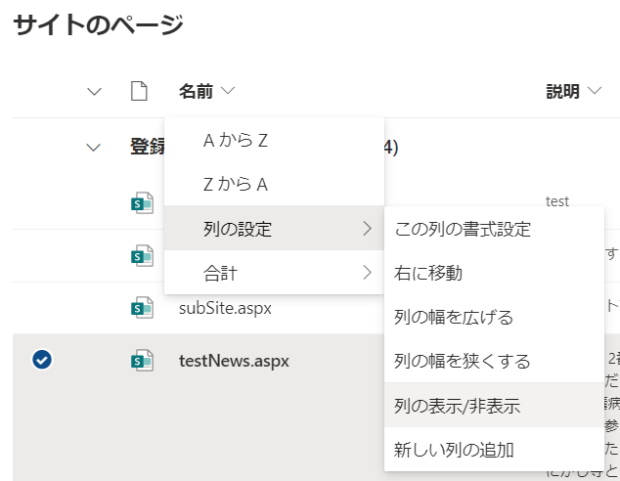
「説明」と「ID」列を表示させるため、チェックをいれて「適用」をクリックします。
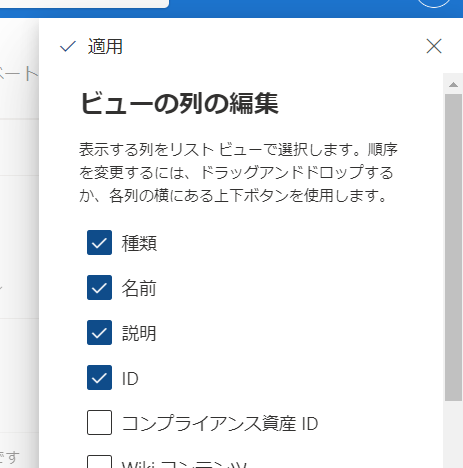
各ページのIDがわかりました。今回は説明テキストが250文字以降省略されている部分を取得するため、ID5をサンプルとしてつかって作業していきます。
ページの中身を詳しく取得するHTTP要求
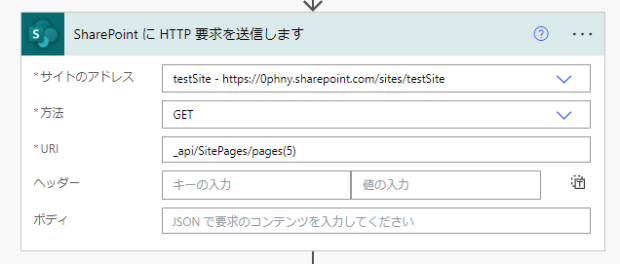
なにかと複雑になりがちなHTTP要求ですが、今回はこれだけです。pages(5)の5が先ほど選んだページのIDです。
テストを実行して結果を見ると、目当ての本文が入っていることがわかります。ただ、JSONの内容はなかなか強烈。
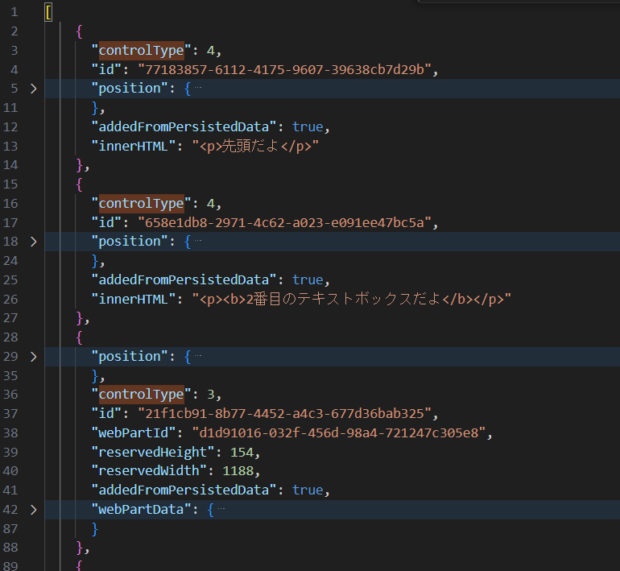
取得したページはこんな感じ。テキストボックスを先頭から2つ。間に画像を入れて、後ろに2つのテキストボックスを追加して文章を入力しています。
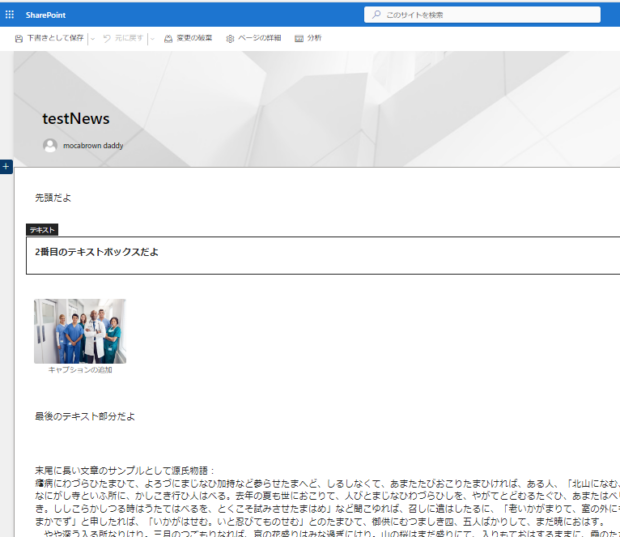
JSONの一部。CanvasControl1の中にcontrolTypeという項目が先頭に入っている配列が含まれていることがわかります。よく見てみると、テキストボックスにはcontrolTypeが4になっているようです。画像は3ですね。
innerHTMLの項目にHTTPタグがついたまま文章が入っているのがわかります。
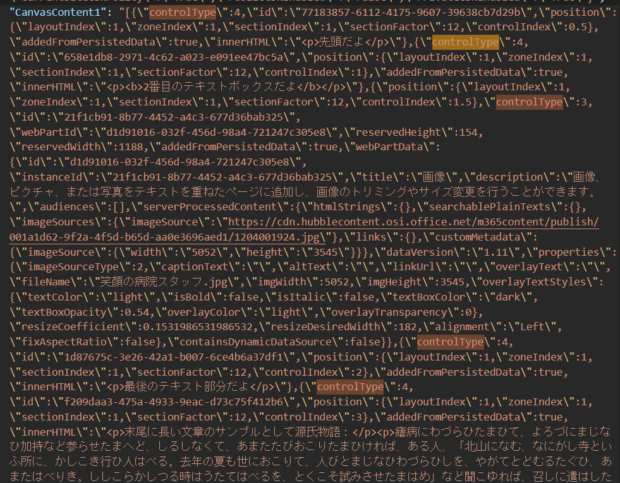
結果をJSONの解析に通す
「SharePointにHTTP要求を送信します」アクションをテスト実行した結果のJSON文字列をコピーしておきます。JSONの解析の「サンプルの作成」をクリックした後のページにはりつけて完了をクリックします。
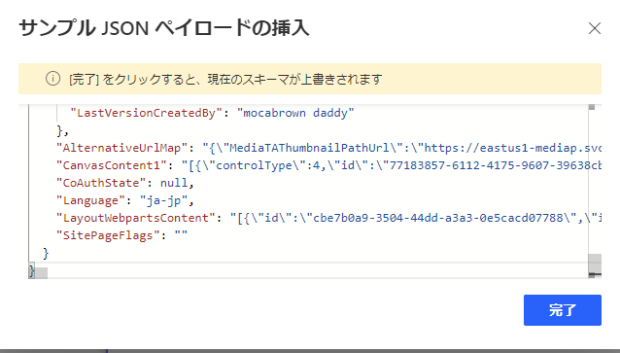
コンテンツには、「SharePointにHTTP要求を送信します」の本文を入れます。
その下に「作成」アクションを追加して、JSONの解析の結果からCanvasContent1の中身を取り出せるように式を入力します。「作成」の名前はここではcontent配列に変えてあります。
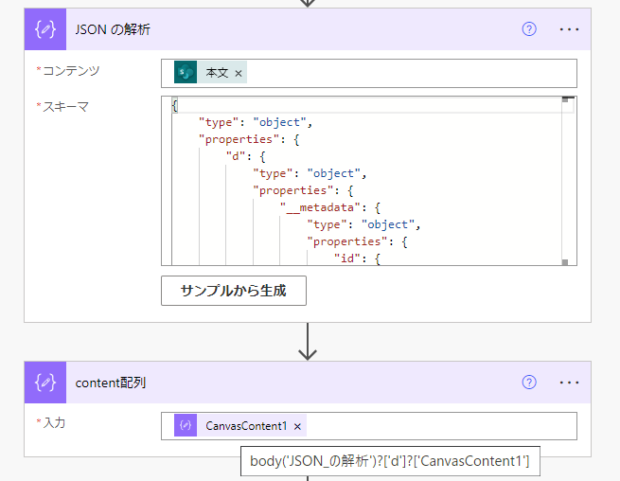
body('JSON_の解析')?['d']?['CanvasContent1']実行してみると、CanvasContent1の中身だけが取り出せました。JSONの配列になっているので、この結果を再度JSON解析に通します。
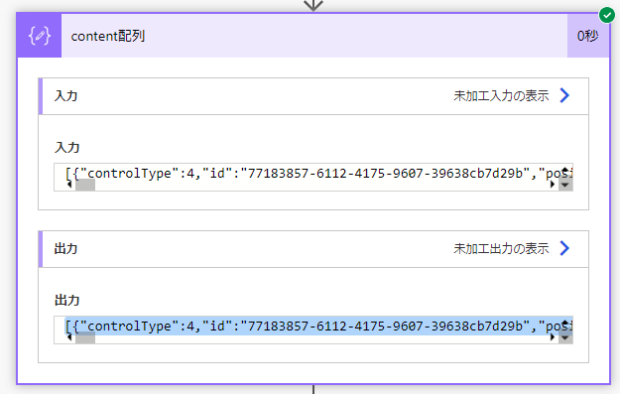
手順はさきほどと同じです。スキーマをcontent配列の結果JSONをサンプルにして作成させます。再度テスト実行します。
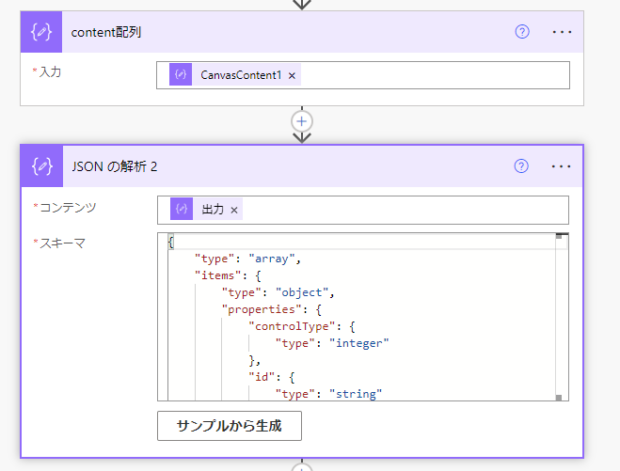
目論見通り、ページのアイテムごとに内容が取得できています。テキストボックスが4だというのがわかります。どうやら、ページの上から順番にならんでいるようです。
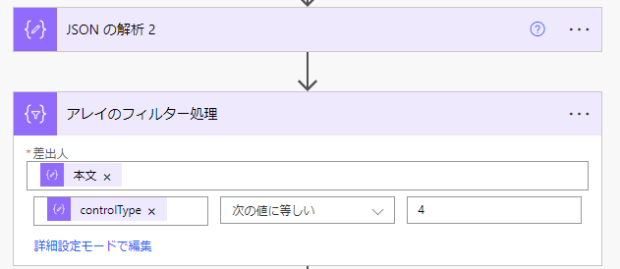
今回取り出したいのはテキストだけなので、controlTypeが4のものだけをフィルターをかけます。
ばらばらのinnerHTMLの中身文章をくっつける
「選択」アクションをテキストモードに切り替えて、マップにinnerHTMLだけを取り出すように式を入れます。
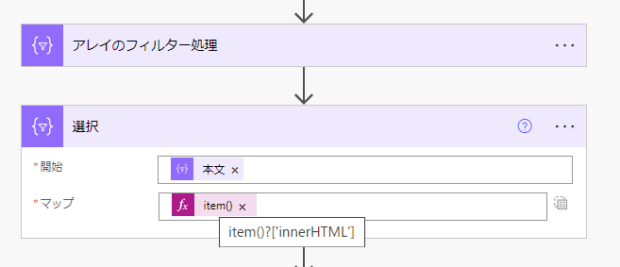
結果をみるとちょっと驚きますが、辞書型ではなくシンプルな配列になります。
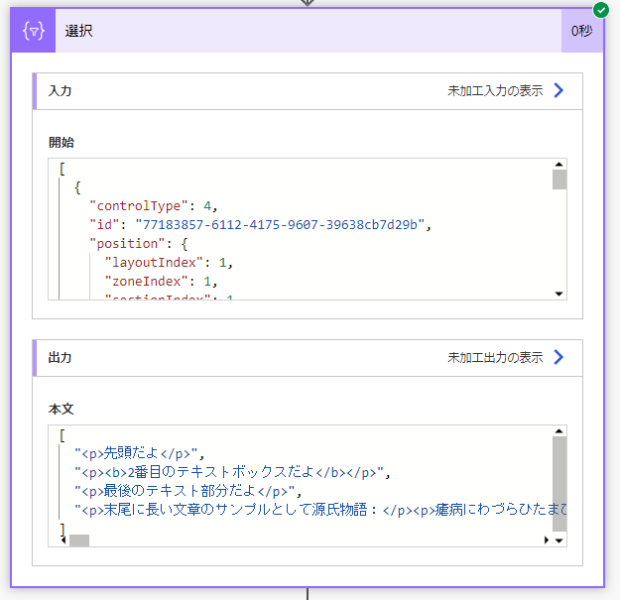
あとは、配列を関数をつかってくっつけてやればよいです。「作成」アクションをもう一つ用意して、join関数をつかうため、式を以下のように設定してやります。
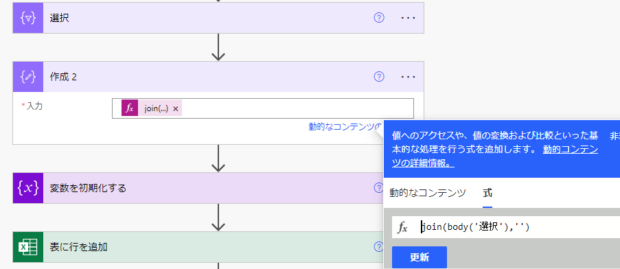
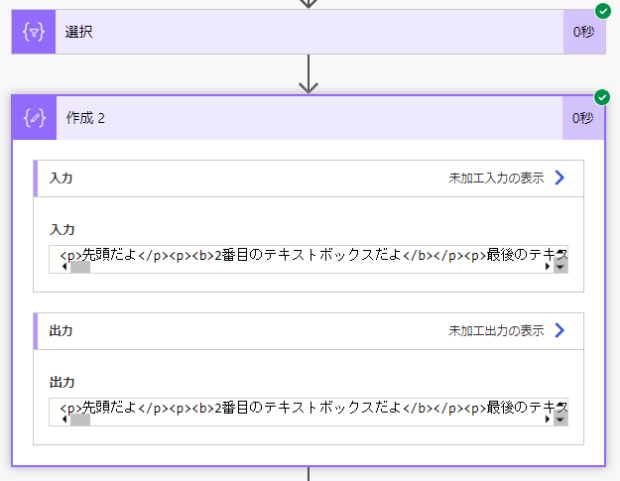
join(body('選択'),'')ばっちり、配列の中身が連結されて一つの文章になりました。
SharePointに書き出し先を用意
OneDriveでもよいですが、今回はSharePointのドキュメントに適当なExcelファイルを置いてテーブルを作りました。
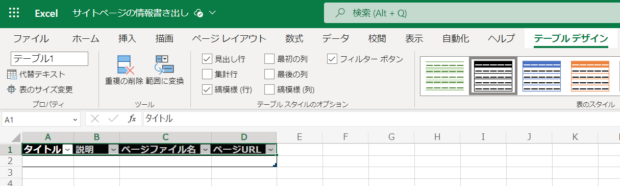
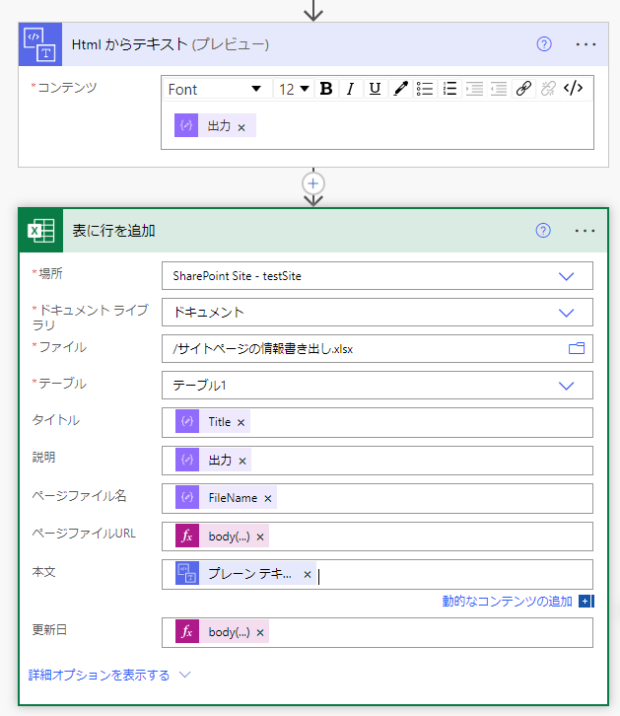
「表に行を追加」アクションを加えます。つくったExcelファイルを指定すると、テーブルの列名が表示されます。
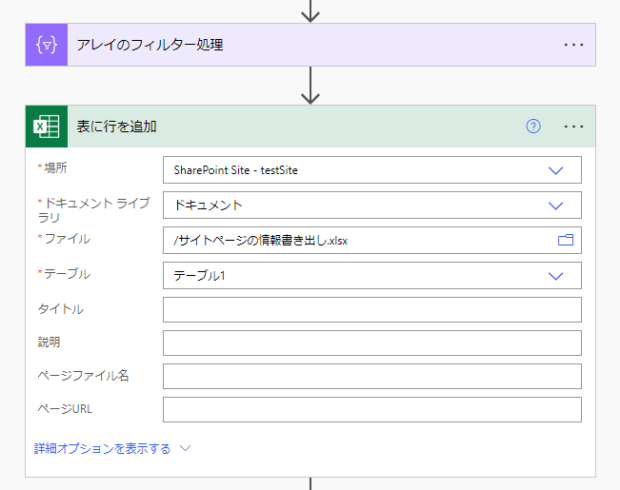
説明列には先ほどinnerHTMLの内容を連結した「作成2」の出力を。
タイトルはJSONの解析の中にあるので、式で直接場所を指定して取得しました。
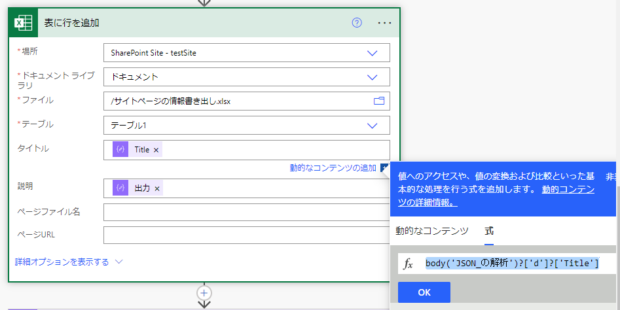
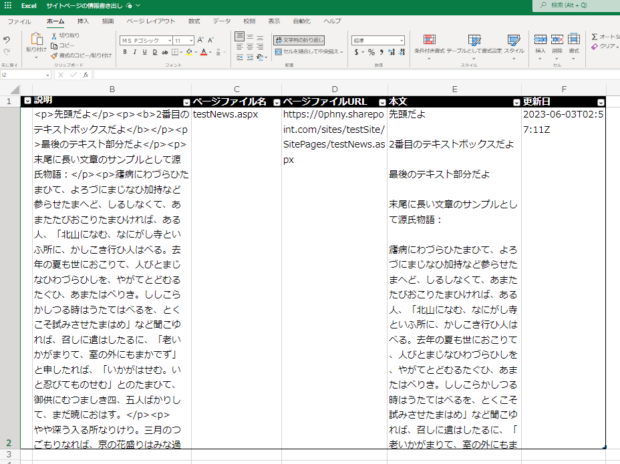
テストを実行すると、Excelファイルにタイトルと説明が表示されました。
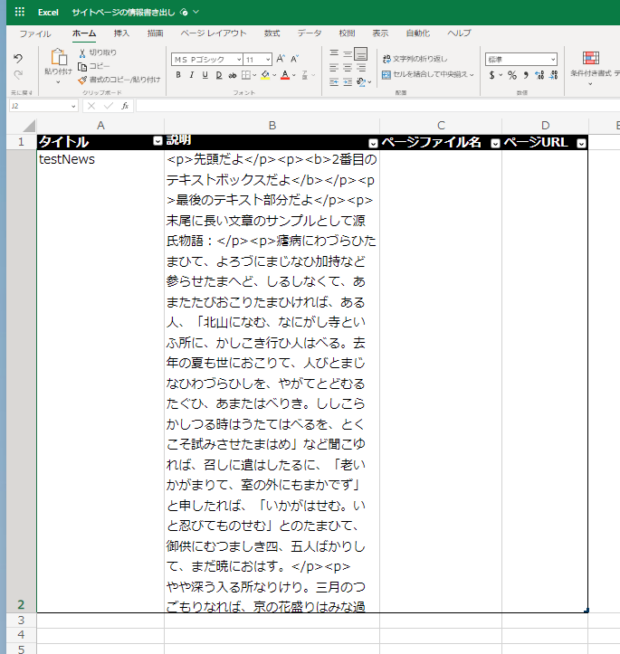
少し項目を増やしてみました。各項目の式は以下のとおりです。本文には「HTMLからテキスト(プレビュー)」をとおしてHTMLタグを取り除いたものを配置しています。
| タイトル | body('JSON_の解析’)?['d’]?['Title’] |
| 説明 | outputs('作成_2’) |
| ページファイル名 | body('JSON_の解析’)?['d’]?['FileName’] |
| ページファイルURL | body('JSON_の解析’)?['d’]?['AbsoluteUrl’] |
| 本文 | body('Html_からテキスト’) |
| 更新日 | body('JSON_の解析’)?['d’]?['Modified’] |
あとはループでリストにあるページを順番に取得すればよい
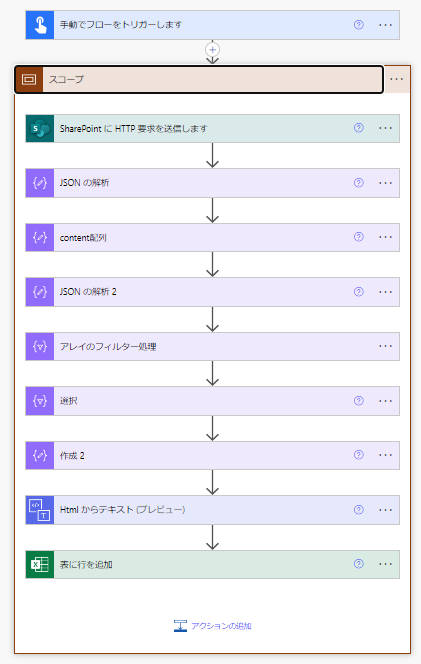
ApplyToEachの中にいま作った処理をいれて、リストに存在するIDから順番に情報を取り出せばよいですが、ひとまず一連の処理を「スコープ」の中にいれてまとめました。
ApplyToEachの中にいれて、「複数の項目の取得」の結果から「Value」を「伊瀬rンの手順から出力を選択」にいれてやります。
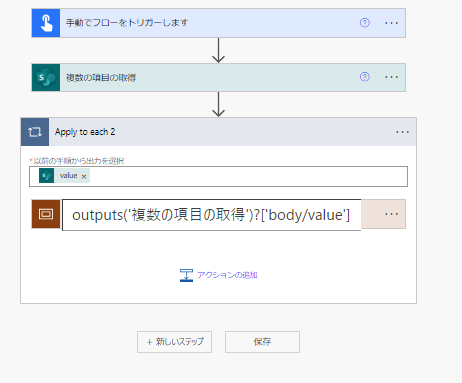
HTTP要求のURIのなかでは、ページのIDを差し替えていくので、このようにします。
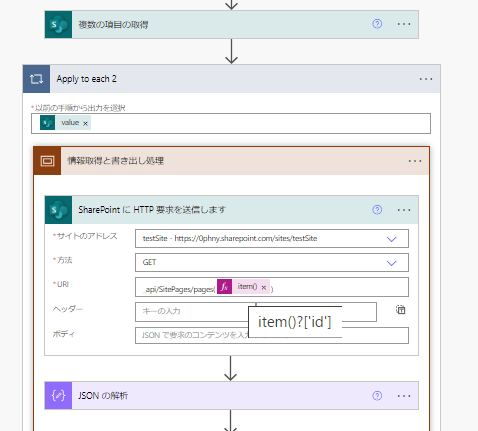
実行すると、一部でエラーがでた
実行してみると、IDを順番にたどってExcelファイルに情報を書き出すことができましたが、いちぶのIDでエラーがでました。
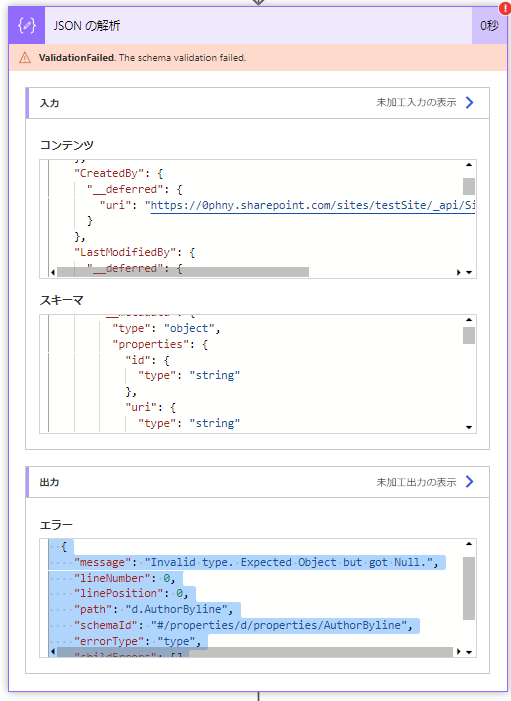
ループのなかのJSON解析でエラーがでています。エラーの中身をみると、
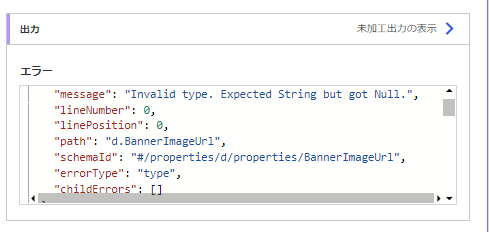
"message": "Invalid type. Expected Object but got Null."と書かれています。タイプが違って、Nullは受け入れないことになっているのに、Nullが届いたということです。
"schemaId": "#/properties/d/properties/AuthorByline",ここを見ると、エラーがでた箇所がわかります。/AuthorBylineという箇所です。
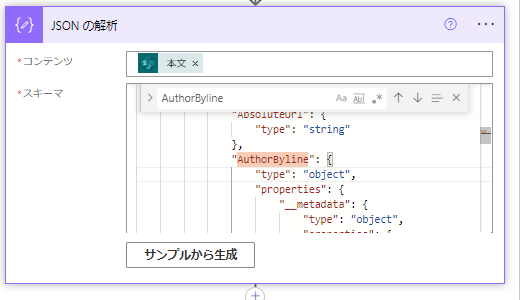
「JSONの解析」に設定してあるスキーマの見直しを行います。スキーマのなかから「AuthorByline」を探します。CTRL+Fで検索ができるのですぐ見つかります。
Typeは"Object"となっています。これを書き換えます。
"type": ["object","null"],Typeはobjectだけではなくてnullも、という複数の項目を受け付けるようにするので、[]で囲って配列にします。後ろにあるカンマを消してしまわないように注意です。
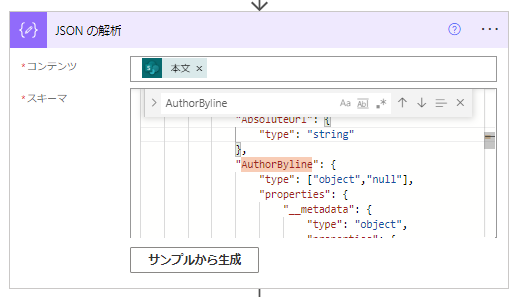
もう一度テスト実行してみると、こんどは/BannerImageUrlにもnullが届いたと警告が・・・。地道にエラー箇所のTypeにnullも受け付けるように加えていきます。
よくチェックすると、エラーが出ているのは「ホーム」
エラーがでているのは1ページだけ。IDは1番。どうも怪しいとおもったら、システムによって自動作成されるページでした。
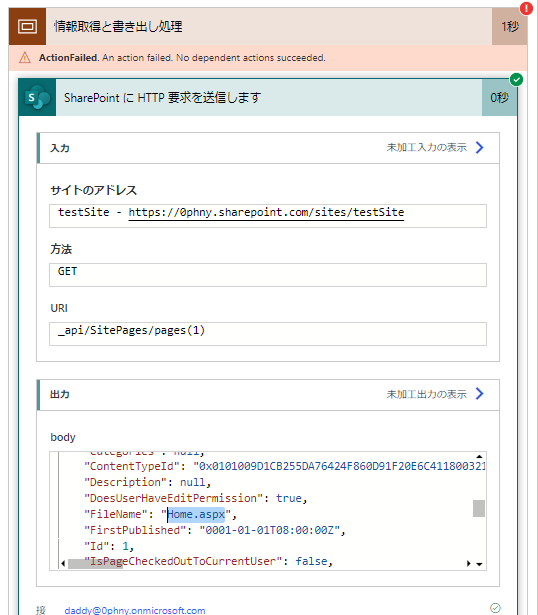
システムで自動作成されたページと、自分で作ったページを見分けられる箇所はないか確認してみると、ページの作成者を示す「AuthorByline」の項目が、ホームのページではnullになっていました。自分でつくったページには、ここにページ作成者のIDなどが入っています。これを条件分けのキーに使えそうです。
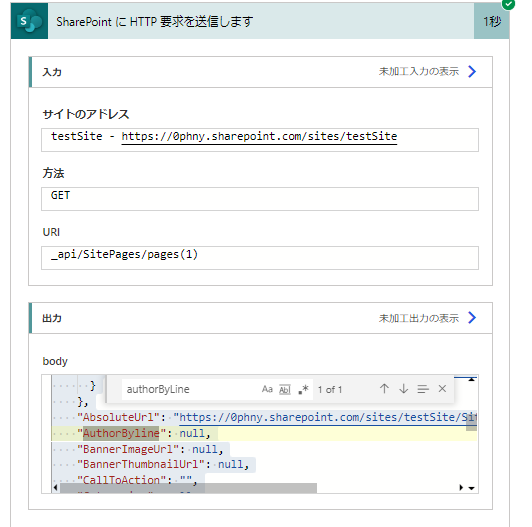
条件の左辺にはauthorBylineの中身をこのように指定します。右辺はnullですが、これも式のなかで指定してやります。文字列としてnullを入力しても反応しません。「次の値に等しくない」で判定させて、はいの場合に一連の処理をいれています。つまり、システムが作成したページは無視します。
body('SharePoint_に_HTTP_要求を送信します')?['d']?['AuthorByline']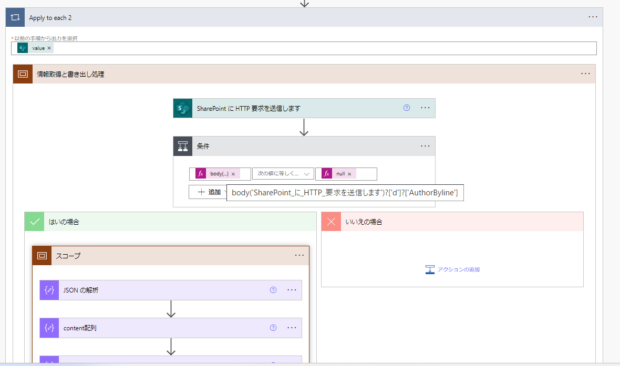
結果はようやく成功。すべてのページの中身のテキストが、省略されることなく取り出せました。